FIMS News
Contact Information
FIMS Communications
Becky Blue
Email
519-661-2111x88493
FIMS & Nursing Building
Rm 2060C
LiT.RL team takes on fake news in the DataCup challenge
 LiT.RL team L-R: Yimin Chen, Chris Brogly, Sarah Cornwell, Victoria Rubin, Tolu Asubiaro, and new LiT.RL recruit Nicole Delellis. (Photo credit: Ellen McGran)
LiT.RL team L-R: Yimin Chen, Chris Brogly, Sarah Cornwell, Victoria Rubin, Tolu Asubiaro, and new LiT.RL recruit Nicole Delellis. (Photo credit: Ellen McGran)
October 21, 2019
In 2010, when Professor Victoria Rubin began researching the particulars of how lies and deception are constructed within language, Facebook’s transformation into an influential news-sharing global machine, Donald Trump’s presidency, and his regular characterizations of mainstream media organizations as “fake news”, were all distant future events.
As 2020 approaches, Facebook is as prominent as ever, Trump is up for reelection, and the scourge of malicious digital mis-information and dis-information is ever increasing. People around the world are struggling to determine what the term fake news really means. And many of them are wondering the same thing: can the “fake news” problem even be solved?
“It’s an extremely complex problem,” explains Rubin, who teaches Library and Information Science in the Faculty of Information and Media Studies at Western University.
“The nature of the problem itself is so complicated that not only do you have to point out whether something is true or false, but you also have to provide sufficient evidence that would convince somebody else to believe that this is true (or false). And even with evidence some issues are still contentious.”
It’s a bedeviling problem that speaks to human psychology and linguistics as much as it does to computer science and artificial intelligence. This year serious money is being put on the line to encourage researchers like Rubin, along with non-profits, corporations and individuals, to collectively search for technological, automated solutions.
One million dollars in prize money is being offered through the DataCup, a Canadian-based competition that challenges participants to solve major societal or industry problems of global significance. Rubin and her research team LiT.RL, made up of four doctoral students in library and information science and health information science, are taking on the challenge. The team also has the support of the FIMS Dean’s Office in pursuing this opportunity.
Rubin says the competition is a natural extension of what they were already doing. She and her research team have been working on identifying deceptiveness in online content for years. What began as a study into the general principles of deceptiveness in language grew into a project to develop artificial intelligence-based tools to directly flag content likely to be deceptive or misleading, for example satire or clickbait. Now it has taken on a new dimension.
“DataCup offers a new step in this logical sequence of research and development where it’s moving away from the idea of general deceptiveness in a piece of news to verifying statements one-by-one,” says Rubin.
It’s a response to the increasing specter of malicious influencers meddling in public affairs for political or financial gain, via the manipulation of public opinion and attitudes using news-like content that appears to be credible.
Winning the prize means being able not only to accurately identify false information using artificial intelligence, but also being able to retrieve and supply corroborating evidence to support the conclusion.
At first glance this doesn’t seem like the type of technological solution that library and information science scholars would be accustomed to developing. But at its most basic, identifying deceptiveness in the language found online is about data analysis.
Rubin explains that she and her team apply the principles of natural language processing, meaning they analyze the ways in which language is used to express various phenomena. For example, they may look at the use of emotion in language, the structure of sentences, or the number of pronouns and adjectives used in both truthful speech and deceptive speech.
“There is a bit of psychology knowledge behind that. It has been known for the last 40 to 50 years in psychology research that people who tell the truth say it in fundamentally different ways than people who lie. There are some qualitative and quantitative differences that we expect between these truthful texts and deceptive texts.”
After a sufficient base of samples has been analyzed, a model starts to emerge of what truthful speech looks like versus deceptive speech. These models can then be used to develop an algorithm that is capable of picking out the different categories of speech on its own.
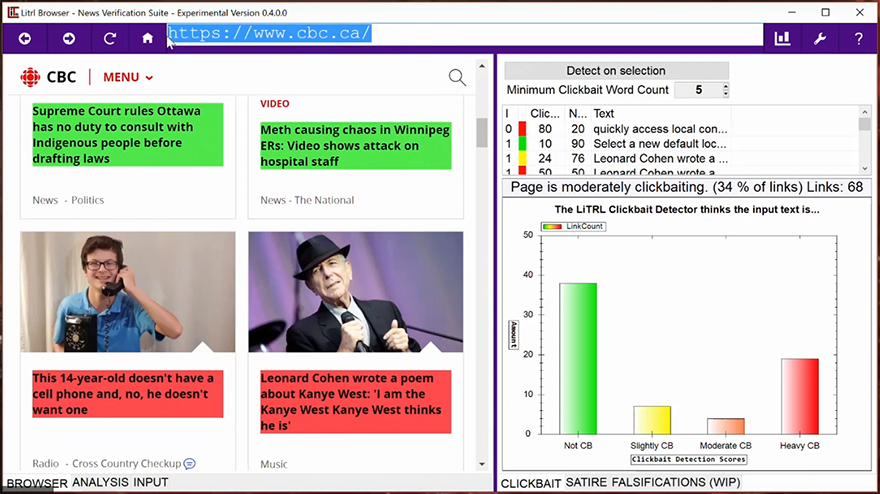
The LiT.RL team already has an algorithm that’s pretty good at picking out satire and clickbait (see the News Verification Browser). For the DataCup it needs to be capable of identifying content as True, Partly True, or False. Placing in the top 10 means moving onto Phase 2, which involves developing an automated method to supply evidence that supports your algorithm’s conclusion.
 Working to find solutions are the team’s two language analysts, LIS doctoral students Sarah Cornwell and Yimin Chen, and two tech specialists, LIS doctoral student Tolu Asubiaro and HIS doctoral student Chris Brogly. Together with team leader Victoria Rubin, they use the sum of their expertise and talents to approach a difficult problem that has so far eluded solutions.
Working to find solutions are the team’s two language analysts, LIS doctoral students Sarah Cornwell and Yimin Chen, and two tech specialists, LIS doctoral student Tolu Asubiaro and HIS doctoral student Chris Brogly. Together with team leader Victoria Rubin, they use the sum of their expertise and talents to approach a difficult problem that has so far eluded solutions.
It is important to try. As Rubin notes, humans are notoriously bad at detecting deceptiveness while navigating their various digital hangouts, especially when taking into account inherent biases.
“Some users online, most of us actually, are time constrained. Our attention wanders and we’re prone to not reading news very carefully. If we’re gullible to what’s being presented we’re more likely to share something that seems to be consistent with our beliefs. The issue is that the people who are reading the news are somewhat compromised and more likely to spread things that are not true.”
Add to that the fact that platforms like Facebook and Twitter are only lightly regulated, and that there is a whole economy out there based on fake news, and forces conspire against our ability to easily screen out false information.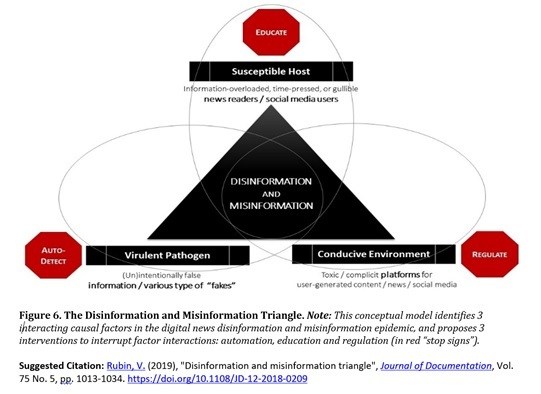 For this reason, Rubin says that developing artificial intelligence that can flag the more easily detectable examples of deceptive information is only part of the solution. Human brain power is still required when it comes to distinguishing nuances. She sees educating users and more tightly regulating platforms as two other key components to addressing the issue.
For this reason, Rubin says that developing artificial intelligence that can flag the more easily detectable examples of deceptive information is only part of the solution. Human brain power is still required when it comes to distinguishing nuances. She sees educating users and more tightly regulating platforms as two other key components to addressing the issue.
“It’s extremely important to implement these three different aspects, in order not to undermine our democratic processes. It’s important to inform our citizens properly, and not instigate uncivil conversations. It’s in our interest in many ways, politically, socially and financially,” says Rubin.
Phase 1 of the DataCup concludes on November 19, 2019. The 10 teams with the best performances will advance to Phase 2, which runs until May 8, 2020.
For more information about LiT.RL, visit their website.
For more information about the Faculty of Information and Media Studies, visit their website.
